개발로그/그림으로 공부하는 IT 인프라 구조
[1장] 인프라 아키텍처를 살펴보자
1.1 인프라란 무엇일까?
- 인프라를 우리말로 하면 기반. 생활을 지탱하는 바탕이나 토대.
- 인프라 아키텍처는 IT인프라의 구조.
- 인터넷 검색 시스템, 항공 회사 발권 시스템, 편의점의 계산대 등 모두가 이용 방법이나 사용자가 다르지만 IT 인프라 위에서 동작하고 있음
1.2 집약형과 분할형 아키텍처
1.2.1 집약형 아키텍처

- 하나의 컴퓨터로 모든 처리를 함
- 과거에 모든 업무를 처리하던 대형 컴퓨터는 '범용 장비', '호스트', '메인 프레임' 등으로 불림.
- 주요 업무를 모두 한 대로 처리하기 때문에 장비 고장 등으로 업무가 멈추지 않도록 해야 함
- 컴퓨터를 구성하는 주요 부품을 다중화하여 하나가 고장 나더라도 업무를 계속할 수 있도록 함
- 복수의 서로 다른 업무 처리를 동시에 실행할 수 있도록 유한 리소스 관리. 하나의 처리가 실수로 대량의 요청을 보내더라도 다른 처리에 영향을 주지 않도록 되어 있음.
| 장점 | 단점 |
| 한 대의 대형 컴퓨터만 있으면 되므로 구성이 간단 | 대형 컴퓨터의 도입 비용과 유지 비용이 비쌈 |
| 대형 컴퓨터의 리소스 관리나 이중화에 의해 안정성이 높고 고성능 | 확장성에 한계 |
1.2.2 분할형 아키텍처
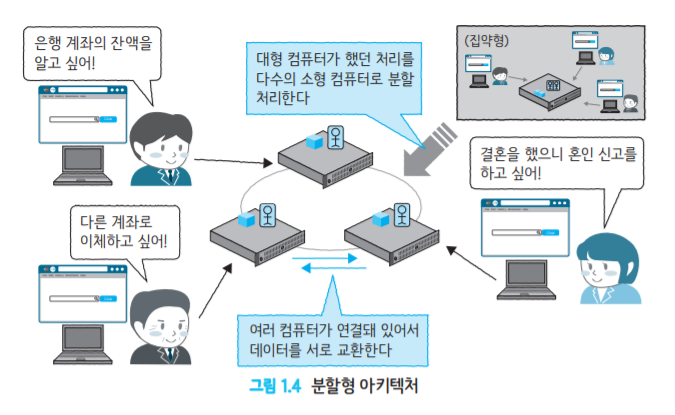
- 여러 대의 컴퓨터를 조합해서 하나의 시스템을 구축하는 구조
- 여러 대의 컴퓨터를 이용해 한 대가 고장나도 안정성 담보
- 표준 OS나 개발 언어를 이용하기 때문에 '오픈 시스템'
- 여러 대의 컴퓨터를 연결해서 이용하기 때문에 '분산 시스템'
| 장점 | 단점 |
| 낮은 비용으로 시스템을 구축할 수 있음 | 대수가 늘어나면 관리 구조가 복잡해짐 |
| 서버 대수를 늘릴 수 있기 때문에 확장성이 높음 | 한 대가 망가지면 영향 범위를 최소화하기 위한 구조를 검토해야 함 |
물리 서버와 논리 서버의 차이
- 분할형 아키텍처에서 이용되는 컴퓨터를 특정 역할에 특화된 것을 의미하는 '서버'라고 부름
- 물리 서버는 컴퓨터 자체를 가리키는 것
- 논리 서버는 컴퓨터에서 동작하고 있는 소프트웨어 (DB 서버, 웹 서버)
1.3 수직 분할형 아키텍처
서버별로 다른 역할을 담당하는 수직 분할형 아키텍처
1.3.1 클라이언트-서버형 아키텍처
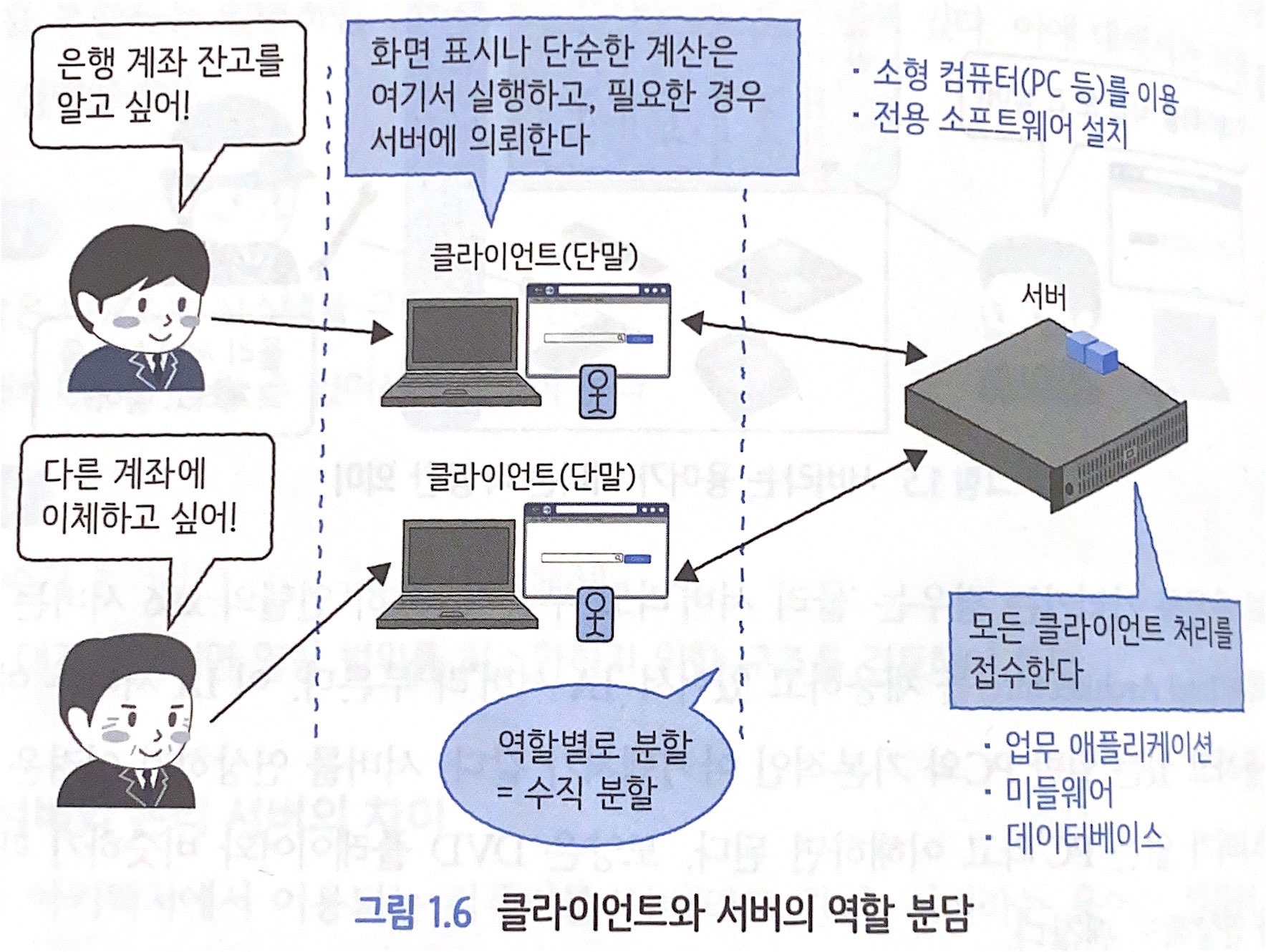
- 업무 애플리케이션, 미들웨어, 데이터베이스 등의 소프트웨어를 물리 서버 상에서 운영
- 소프트웨어에 '클라이언트' 또는 '단말'이라 불리는 소형 컴퓨터가 접속해서 이용하는 형태
- 클라이언트(PC, 스마트폰, 태블릿) 측에 전용 소프트웨어를 설치해야 함.
| 장점 | 단점 |
| 클라이언트 측에서 많은 처리를 실행할 수 있어 소수의 서버로 다수의 클라이언트를 처리할 수 있음 |
클라이언트 측의 소프트웨어 정기 업데이트가 필요 |
| 서버 확장성에 한계 발생 가능 |
1.3.2 3계층형 아키텍처

- 클라이언트-서버형 아키텍처의 단점 개선
- 프레젠테이션 계층 : 사용자 입력을 받음, 웹 브라우저 화면을 표시함
- 애플리케이션 계층 : 사용자 요청(Request)에 따라 업무 처리
- 데이터 계층 : 애플리케이션 계층의 요청에 따라 데이터 입출력
- 사용자가 웹 브라우저를 통해 시스템에 접속 ➡️ 웹 서버가 요청을 애플리케이션 계층의 애플리케이션 서버(AP 서버)에 전달 ➡️ 데이터 계층의 데이터베이스(DB 서버)에 데이터 요청
| 장점 | 단점 |
| 서버 부하 집중 개선 | 구조가 클라이언트-서버보다 복잡 |
| 클라이언트 단말의 정기 업데이트 불필요 | |
| '처리 반환'에 의한 서버 부하 저감 |
1.4 수평 분할형 아키텍처
용도가 같은 서버를 늘려나가는 방식의 수평 분할형 아키텍처
서버 대수가 늘어나면 한 대가 시스템에 주는 영향력이 낮아져서 안정성 향상되며 전체적인 성능 향상 실현 가능
1.4.1 단순 수평 분할형 아키텍처

- Sharding(샤딩)이나 Partitioning(파티셔닝)이라 부르기도 함
- 거래상으로 멀리 떨어진 시스템, 각 거점이 완전히 독립된 운영을 하고 있는 경우에 적합
- 많은 사용자가 있는 SNS 웹 서비스에서는 사용자 ID를 기준으로 서버를 분할(Sharding)하는 경우가 있음
| 장점 | 단점 |
| 수평으로 서버를 늘리기 때문에 확장성 향상 | 데이터를 일원화해서 볼 수 없음 |
| 분할한 시스템이 독립적으로 운영되므로 서로 영향을 주지 않음 | 애플리케이션 업데이트는 양쪽을 동시에 해 주어야 함 |
| 처리량이 균등하게 분할되어 있지 않으면 서버별 처리량에 치우침 생김 |
1.4.2 공유형 아키텍처

- 일부 계층에서 상호 접속 이루어짐
- 보안이나 관리상 유리함
| 장점 | 단점 |
| 수평으로 서버를 늘리기 때문에 확장성 향상 | 분할한 시스템 간 독립성이 낮아짐 |
| 분할한 시스템이 서로 다른 시스템의 데이터를 참조 가능 | 공유한 계층의 확장성이 낮아짐 |
1.5 지리 분할형 아키텍처
지리적으로 분할하는 아키텍처는 업무 연속성 및 시스템 가용성을 높이기 위한 방식
1.5.1 스탠바이형 아키텍처
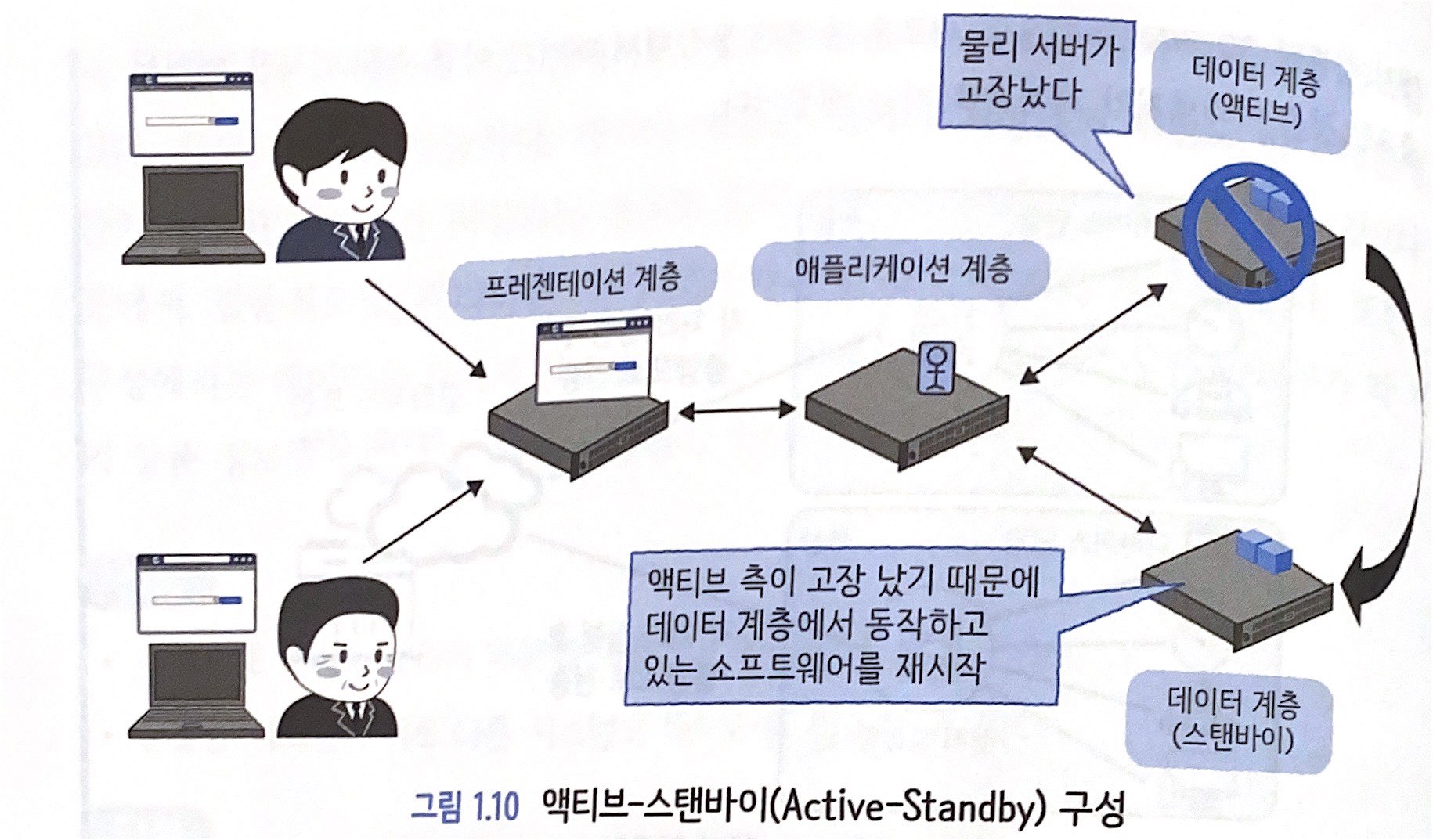
- 스탠바이 구성, HA(High Availability) 구성, 액티브-스탠바이 구성
- 물리 서버를 최소 두 대를 준비하여 한 대가 고장 나면 가동 중인 소프트웨어를 다른 한 대로 옮겨서 운영
- 소프트웨어 재시작을 자동으로 하는 구조를 '페일오버(Failover)' (페일, F/O라고도 씀)
- 물리 서버가 고장나지 않을 때는 페일오버 대상 서버(스탠바이)가 놀고 있게 되어 리소스 측면에서의 낭비 발생
- 스탠바이를 따로 두지 않고 양쪽 서버를 동시에 교차 이용(한쪽이 고장 나면 다른 한 쪽이 양쪽을 처리)하는 방식 사용하기도.
1.5.2 재해 대책형 아키텍처

- 특정 데이터 센터(사이트)에 있는 상용 환경에 고장이 발생하면 다른 사이트에 있는 재해 대책 환경에서 업무 처리를 재개하는 재해 복구(Disaster Recovery)
- 1.11처럼 서버 장비를 최소 구성 및 동시 구성으로 별도 사이트에 배치
- 재해 발생 시 1.12와 같이 전혀 다른 사이트에 있는 정보 이용
- 애플리케이션 최신화와 데이터 최신화에서 문제 발생
- 저장소 장비 기능, OS 기능, 데이터베이스 기능 등 동기 처리를 위한 방법은 여러 가지
좋아요2
공유하기
게시글 관리
'개발로그 > 그림으로 공부하는 IT 인프라 구조' 카테고리의 다른 글
[2장] 서버를 열어 보자 (2)| 2022.10.14 |
'개발로그/그림으로 공부하는 IT 인프라 구조' Related Articles







[2장] 서버를 열어 보자
떼닝 2022. 10. 14. 22:02
2.1 물리 서버
2.1.1 서버 외관과 설치 장소
- 랙(Rack)에는 서버뿐만 아니라 HDD가 가득 장착되어 있는 저장소나 인터넷 및 LAN을 연결하기 위한 네트워크 스위치 등이 탑재되어 있음
- 서버 설치 시 가장 중요한 정보는 서버 크기(U), 소비 전력(A), 중량(kg)
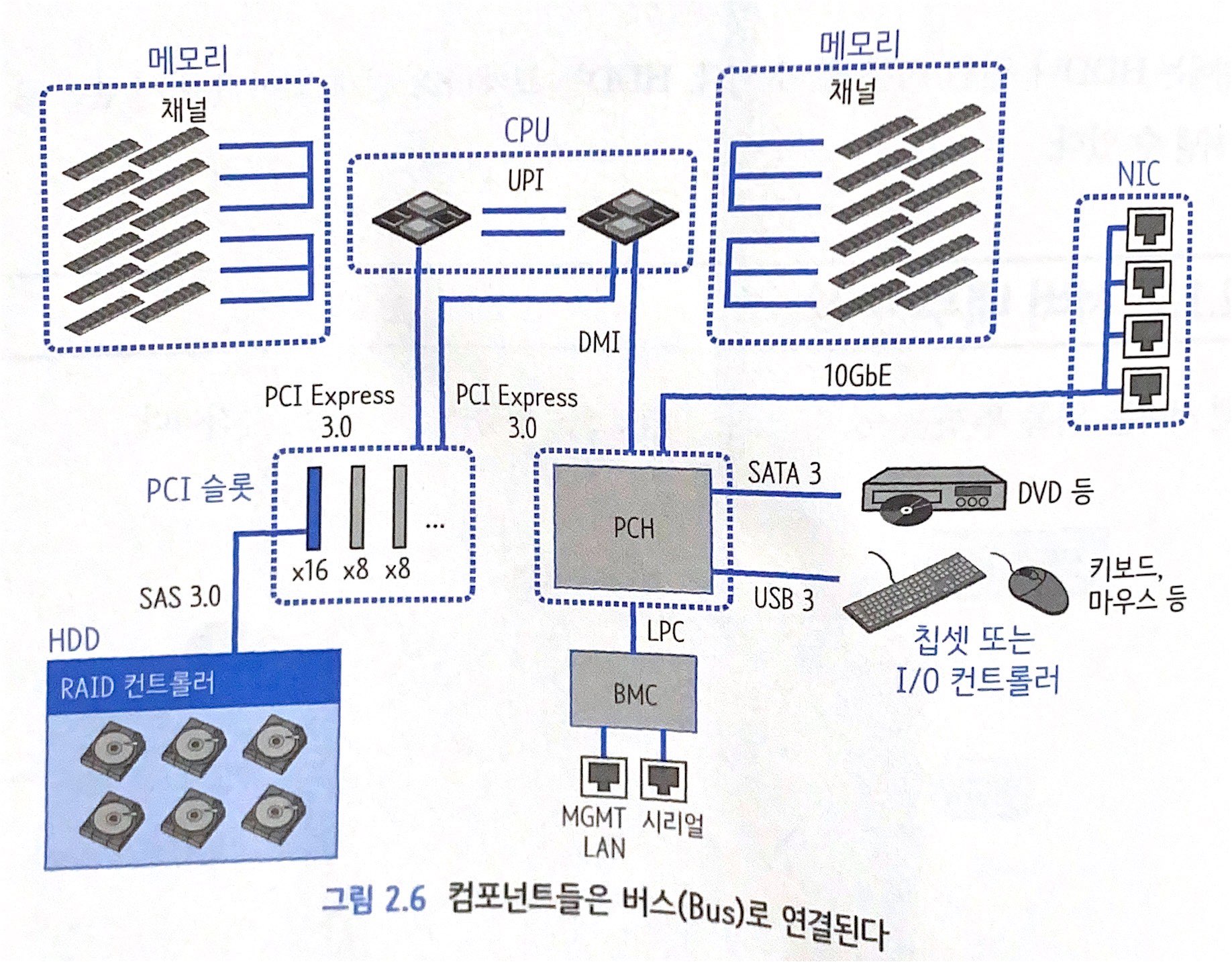
2.1.2 서버 내부 구성
- 컴포넌트를 연결하는 선을 버스(Bus)
- CPU와 메모리는 물리적으로 직접 연결됨
- PCI Express 슬롯은 외부 장치를 연결하는 곳
- Xeon 확장 프로세서 아키텍처에서는 CPU가 PCI를 직접 제어
- 위 그림에서는 칩셋이 네트워크 인터페이스를 4개까지 직접 제어 가능
- BMC(Baseboard Management Controller)는 서버의 HW 상태를 감시하며, 독립적으로 움직임.
- 서버의 H/W에서 장애가 발생한 경우 BMC 콘솔을 통해 서버 상태를 확인하거나 네트워크로 접속해서 서버를 원격으로 재시작 가능
- 서버와 PC는 물리적으로 기본 구성이 같으나 서버는 전원이 이중화되어 있어 장애에 강하고, 대용량 CPU나 메모리가 탑재되어 있는 정도가 PC와 다름
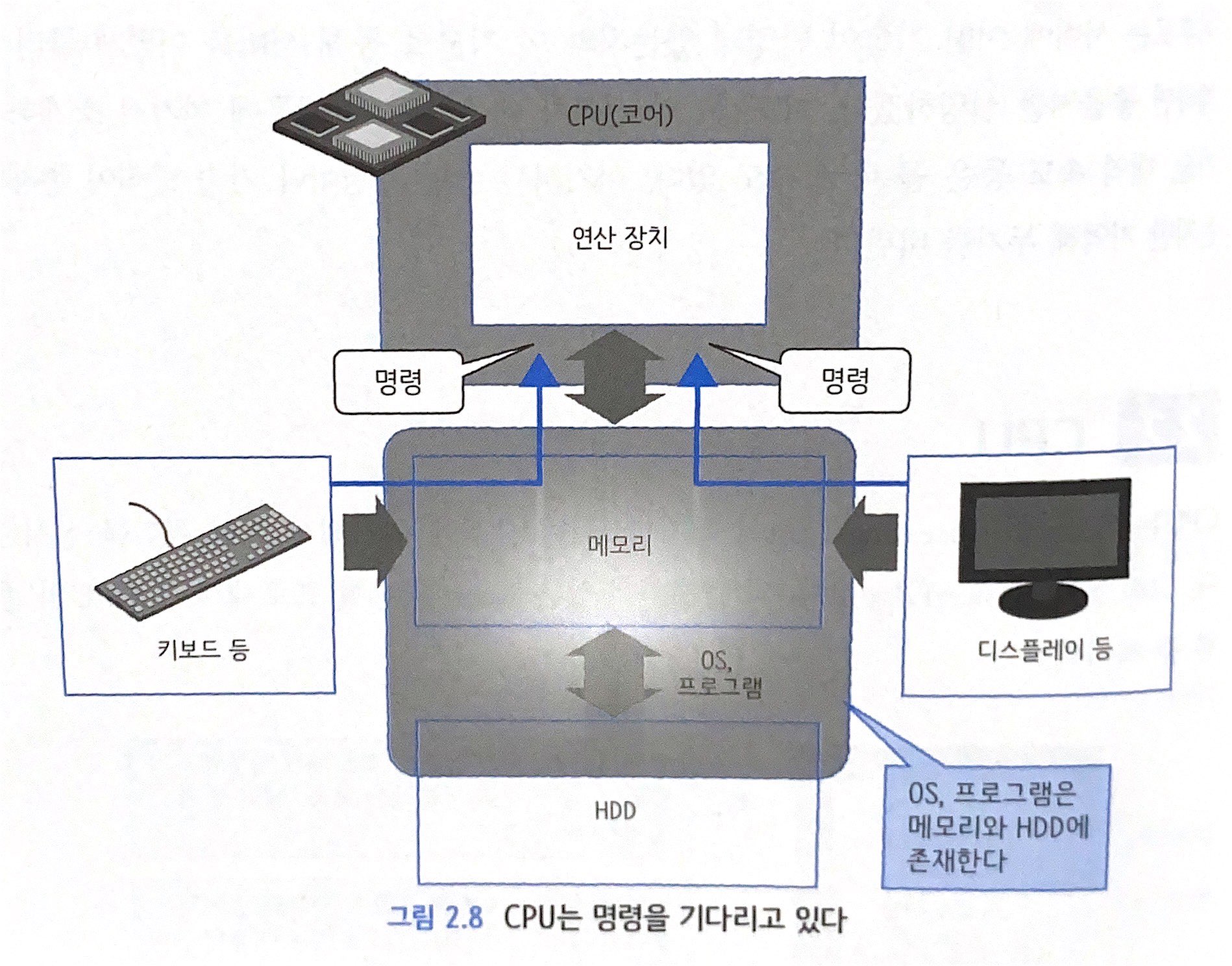
2.2 CPU
- 서버 중심에 위치해서 연산 처리를 실시하는 CPU(Central Processing Unit)
- CPU는 명령을 받아서 연산을 실행하고 결과를 반환하고, 명령과 데이터는 기억 장치나 입출력 장치를 통해 전달됨
- CPU를 '코어(core)'라고 하며, 하나의 CPU에 여러 개의 코어가 존재하는 멀티 코어화 진행 중. 코어는 각자가 독립된 처리 가능
그럼 이건 재귀의 형태라는 걸까...? CPU 자기 스스로 안에 또 CPU가 있는 건가?
- 운영체제(Operating System, OS)에서 동작하는 웹 서버나 데이터베이스의 실체인 '프로세스'와 사용자 키보드, 마우스 등을 통한 입력으로 OS에 명령을 내리고 이를 OS는 또 아래로 보냄
- 키보드나 마우스가 하는 처리를 '끼어들기(Interrupt) 처리'
2.3 메모리
- CPU 옆에 위치하여 CPU에 전달하는 내용이나 데이터를 저장하거나 처리 결과를 받는 메모리(기억 영역)
- 메모리에 저장되는 정보는 영구성이 없어 서버를 재시작하면 데이터가 날아가지만 엑세스를 빠르게 할 수 있어 사용
- CPU 자체에도 레지스터, 1차(L1)/2차(L2) 캐시라는 메모리 존재. 일반 메모리보다 더 빠르지만 용량이 작음
- 여러 단계로 구성 되어 있는 프로세서의 캐시
- 이 아키텍처에서는 L1, L2 캐시에 있는 데이터가 L3에도 존재하여 다른 코어는 자신 이외의 캐시를 확인하지 않고 L3 캐시만 확인
- 메모리를 이용하려면 메모리 컨트롤러를 경유해서 CPU 밖으로 나가야 하는데, 고속 CPU에서는 이러한 처리 지연(Latency)를 허용하지 않기 때문에 가장 자주 사용하는 명령/데이터를 코어 가까운 곳에 배치하고 메모리 영역을 여러 개로 사용
- L1캐시에는 초고속으로 액세스하고 싶은 데이터를
- L2캐시에는 준고속으로 액세스하고 싶은 데이터를 둠
- 미리 데이터를 CPU에 전달해서 처리 지연을 줄이는 메모리의 '메모리 인터리빙(Memory Interleaving)'
- 왼쪽 아래의 메모리 컨트롤러와 메모리와 CPU간 데이터 경로인 채널(Channel)을 아래 그림에서 자세히 표현
- 대부분의 데이터가 연속해서 엑세스가 된다는 규칙을 기반으로 최대 세 개의 채널을 사용해서 데이터 1을 요구하면 데이터 2와 3을 함께 보냄. 먼저 읽음으로써 처리 지연 줄여줌
- 모든 채널의 동일 뱅크에 메모리를 배치함으로써 채널 영역을 많이 사용할 수 있음
- 메모리는 다단계 구조를 가지고 각각의 액세스 속도에 맞게 사용되기 때문에 CPU의 데이터 처리 속도를 줄일 수 있음
2.4 I/O 장치
2.4.1 하드 디스크 드라이브(HDD)
- 메모리에 비해 CPU에서 떨어진 곳에 HDD가 배치되며, 장기 저장 목적의 데이터 저장 장소로 사용됨
- 메모리는 전기가 흐르지 않으면 데이터가 사라지는 반면, 디스크는 전기가 없어도 데이터가 사라지지 않음
- HDD 내부에서 고속으로 회전해서 읽기/쓰기 처리를 하기 때문에 순식간에 액세스할 수 없음
- 최근에는 물리적인 회전 요소를 사용하지 않는 SSD(Solid State Disk, 반도체 디스크) 사용
- SSD는 메모리와 같이 반도체로 만들어졌으나 전기가 없어도 데이터가 사라지지 않으며, 메모리와 기억 장치 간 속도 차이가 거의 없음
- HDD가 많이 탑재된 하드웨어를 '스토리지(Storage, 저장소)'. CPU와 캐시가 존재하고 수많은 HDD 외에도 여러 기능 탑재
- 서버와 I/O 시에는 HDD 가 직접 데이터 교환을 하는 것이 아니라 캐시를 통해서 진행
- 대형 저장소와 연결할 때는 파이버 채널(Fiber Channel, FC)이라는 케이블을 사용해서 SAN(Storage Area Network)이라는 네트워크 경유
- SAN에 접속하기 위한 파이버 채늘 인터페이스를 FC포트. 보통의 서버 시스템 포트에 존재하지 않기 때문에 PCI 슬롯에 HBA라는 카드 삽입
- 캐시라는 메모리 영역에 액세스함으로써 I/O 진행
- 읽기 캐시의 경우 캐시상의 데이터 복사본만 있으면 되지만, 쓰기 시에는 캐시에만 데이터를 기록하고 완료했다고 간주하는 경우 데이터를 잃을 가능성이 있음
- 캐시에 저장해서 쓰기 처리가 종료되기 때무에 고속 I/O를 실현할 수 있다(Write Back)는 것이 장점.
- 대부분의 저장소 제품에서는 이 캐시를 별도의 캐시와 미러링해서 안정성 높임
- 캐시와 HDD에 모두 액세스함으로써 I/O 진행
- 읽기 시에 캐시에 데이터가 없으면 읽기 처리를 위해 액세스, 쓰기 시에는 캐시와 디스크를 모두 읽어서 라이트 백과 비교하고, 더 확실한 쪽에 쓰기 처리를 실시하기 위해 액세스
- 쓰기 캐시의 장점은 없음... (Write Through)
- 기본적으로는 캐시의 장점을 살리기 위해 Write Back으로 설정
2.4.2 네트워크 인터페이스
- 네트워크 인터페이스는 서버와 외부 장비를 연결하기 위한 것으로, 외부 접속용 인터페이스
- 서버 외부 장비로는 LAN(Local Area Network)이나 SAN 어댑터 같은 네트워크에 연결된 다른 서버나 저장소 장치 있음
2.4.3 I/O 제어
- Xeon 확장형 프로세서에는 PCH(Platform Controller Hub)라는 칩셋이 탑재되어 있어 CPU가 제어하는 메모리나 PCIE(PCI Express) 외의 처리 속도가 비교적 늦어도 용서되는 I/O 제어 담당
- PCI의 x8, x16는 PCI의 I/O 회선이 몇 개 연결되는지를 의미. x8이면 8선...
- 각 CPU/칩셋 구조마다 PCI를 연결할 수 있는 회선이 정해져 있는데, Xeon 확장형 프로세서는 각 CPU가 48개의 PCI 회선 존재.
- 하지만 각 서버에는 내부적인 사용 용도도 있으므로, 외부 연결을 위해 사용할 수 있는 PCI 회선 수는 CPU가 처리할 수 있는 총량보다 적음
- 최근에는 대량의 I/O 및 통신 처리를 서버에서 감당하고 있어 PCI 컨트롤러가 병목 지점이 되지 않도록 CPU가 직접 제어
- CPU 외에도 다양한 컨트롤러가 존재함으로써 CPU가 해야 할 연산에 더 집중할 수 있게 됨
- I/O 시에 관련 처리를 가능한 I/O와 가까운 곳(즉, CPU에서 멀리 있는 곳)에서 처리하는 것이 더 효율적임
- CPU와 칩셋의 관계는 역할 분담을 위한 것
2.5 버스
버스(Bus)는 서버 내부에 있는 컴포넌트들을 서로 연결시키는 회선.
버스가 어느 정도의 데이터 전송 능력을 가지고 있는가, 즉 대역이 어느 정도인가가 중요
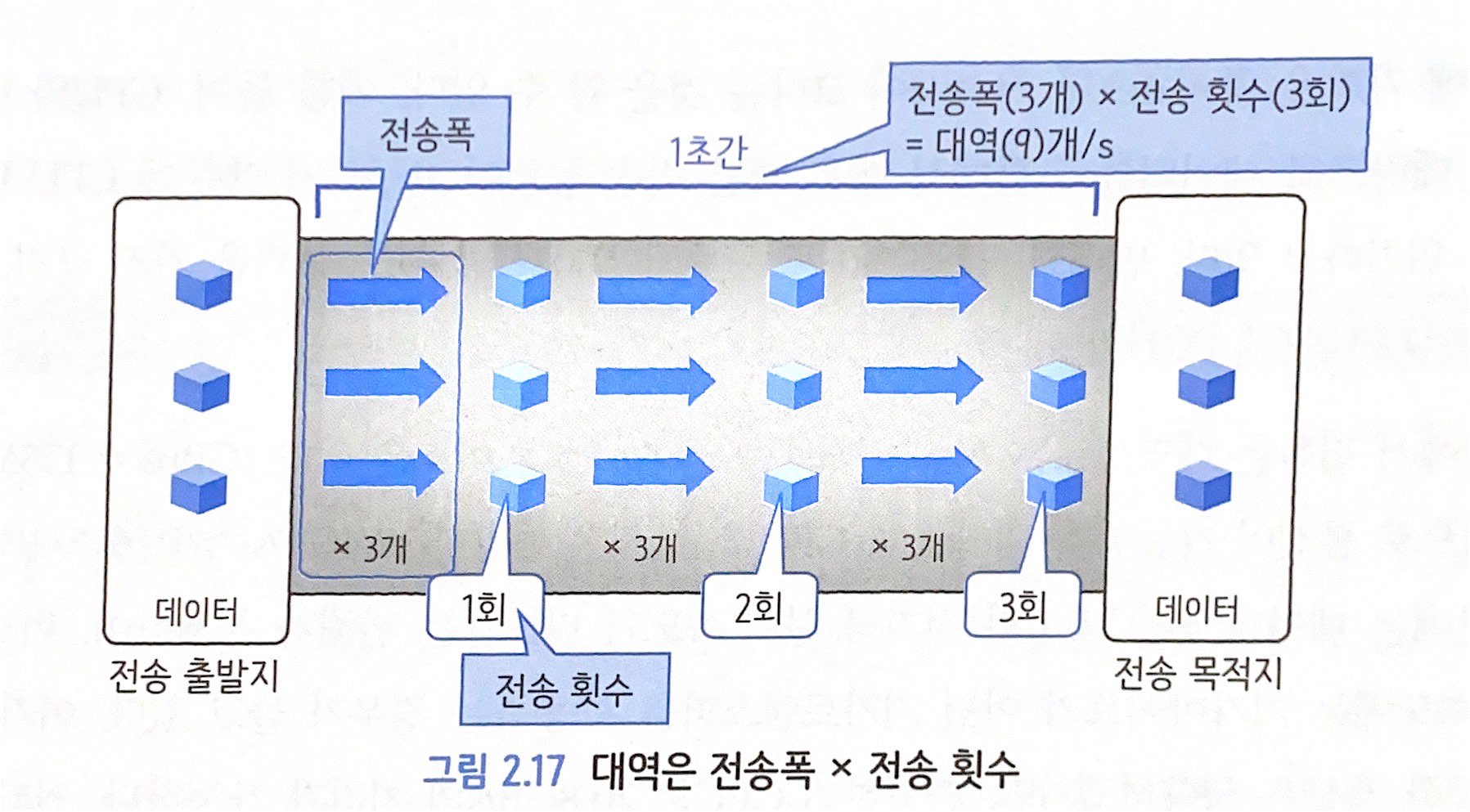
2.5.1 대역 (Throughput)
- 대역은 데이터 전송 능력을 의미. 한 번에 보낼 수 있는 데이터의 폭(전송폭) X 1초에 전송할 수 있는 횟수(전송 횟수)
- 전송 횟수는 1초 / 1 처리당 소요 시간(응답 시간)
2.5.2 버스 대역
- CPU에 가까운 쪽이 1초당 전송량이 크다는 것 확인 가능
- CPU와 메모리는 데이터를 대량으로 교환하기 때문에 매우 빠른 전송 능력이 요구. 메모리는 CPU 바로 앞에 위치
- USB 3.0 포트는 약 500MB/s 전송 능력을 가진 규격으로 저속이기 때문에 PCH 앞에 배치해도 문제 없음
- 버스 흐름에서 중요한 것은 CPU와 장치 사이에 병목 현상(데이터 전송이 어떤 이유로 막혀 있는 상태, Bottleneck)이 없어야 한다는 것
- 외부 장치와 연결을 검토할 때는 버스나 I/O 능력 고려해야 함
좋아요1
공유하기
게시글 관리
'개발로그 > 그림으로 공부하는 IT 인프라 구조' 카테고리의 다른 글
[1장] 인프라 아키텍처를 살펴보자 (0)| 2022.10.13 |
'개발로그/그림으로 공부하는 IT 인프라 구조' Related Articles
more



'코딩' 카테고리의 다른 글
| function sum(a, b) (0) | 2022.11.23 |
|---|---|
| 웹개발 종합반 5주차 (0) | 2022.11.05 |
| 웹개발 종합반 5주차 공부일지 (0) | 2022.11.05 |
| 비개발자를 위한, 웹개발 종합반 4주차 (0) | 2022.11.05 |
| 스파르타코딩클럽 웹개발 종합반(3주차) (0) | 2022.11.03 |



